Using AI for automating financial processes

20 October 2020
Using artificial intelligence in the processes which enable the computer to learn to do tasks natural to the human brain covers many areas. In particular, those that seem simple but, when automated, can streamline the work.
This is, in fact, the essence of the project that we are implementing right now using machine learning. Its goal is to automate financial processes and document workflow in an organization.
The customer asked us to automate the process of handling invoices. The challenge was to process more than a hundred invoices daily and support the workflow of purchase documents, the verification of which required a lot of time.
Typically, every document had to be classified by invoice number, date of issue, payment term, and gross amount.
The main goal of the project was to use AI to identify a contractor based on the information provided in electronic documents. The invoices were both from Polish and foreign contractors and came in various formats.
Having analyzed the problem, we identified 4 key elements of the process:
1. The first element was the identification of documents from Polish contractors.
For virtually all sub-issues, .pdf documents had to be converted into text format. To do this, we used AI-based OCR tools, in particular the upgraded version of LSTM (Long Short-Term Memory).
This way we managed to obtain textual representation of the invoice and easily identify the contractors using their NIP (tax ID) numbers as the main attribute.
2. The second element of the process was the identification of documents from foreign contractors.
An important part of the project was to enable identification of a contractor based on a foreign invoice. In this case, we used AI models leveraging machine learning. These algorithms, however, do not support textual data. Thus we needed a model which would allow for converting the documents into numerical format. As part of the pre-processing stage, we prepared samples. Then we converted the textual form of the set of input documents (corpora) into vectoral representation.
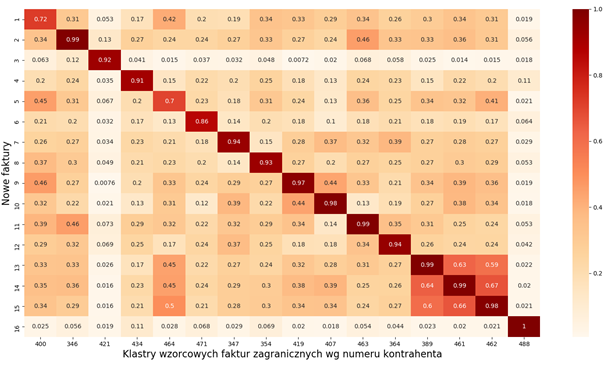
The so called similarity matrix was helpful in developing the best possible model. The matrix uses a heatmap to visualize the degree of similarity between the invoices used to develop the model and sample new documents.
For the initial version of the model, we created a heatmap where every column represented a reference set of invoices of a given contractor. Therefore, each row shows the degree of similarity between a new invoice and every reference set (the darker the color, the greater the similarity).
The figure below presents 16 contractors (foreign invoice clusters) and 16 new invoices.
After modifying the model, we obtained a vectoral format of the documents, which is sufficient for unequivocal assignment of new invoices to the reference set:
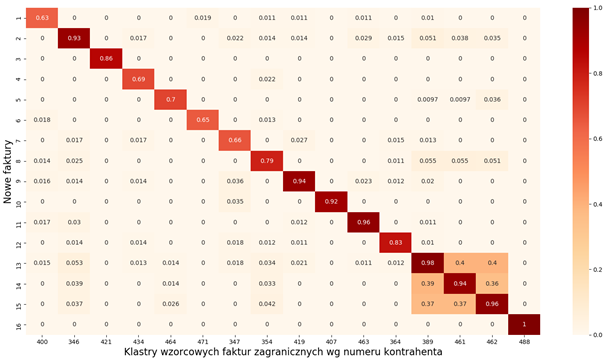
The developed model was used for calculating the vectoral form of the newly received documents. For such document representation, we used the method of identifying the most similar vector from our input set, thus obtaining the searched foreign contractor.
3. The third identified element of the process was downloading information such as invoice number, date of issue etc.
As part of the project, we used machine learning models, including natural language processing, to obtain basic information such as invoice number, date of issue or date of receipt. The word2vec models based on neural networks helped us find words in the documents which were most similar to their reference form.
This is shown in the figure below (source: https://nlp.town/blog/sentence-similarity/).
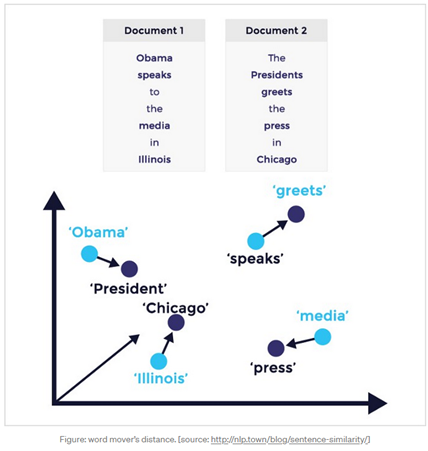
This resulted in identifying the areas in the text which included the searched data. In order to avoid incorrect identification of the areas, our algorithm learns with every new invoice by comparing its suggestion with the data accepted by the system user.
4. The fourth element of the process is describing the invoice and linking it with business artifacts.
We used different methods for automatic description of documents. In this case, we needed an effective algorithm to identify the items in the invoice. We used image processing techniques. This enabled us to find, by comparison with the reference image, geometric coordinates of all items of the newly received invoice.
Below is an example of using this method for finding coins:

For such obtained areas, we used a method of grouping document characters, thus obtaining invoice item as divided into columns. Then we designed a user-configurable interface allowing for mapping the obtained board onto business artifacts.
We implemented the described methods in Python. For integration, we chose an architecture based on sites communicating with one another. The sites written in Python communicate with other application modules stored in Microsoft.Net.
Our specialists develop self-learning solutions to do specific tasks quickly and as effectively as possible.
How to use AI capabilities in your organization?
Contact us for more information: betacom@betacom.com.pl
Share
Kontakt:
- Dariusz Styka
- T: +48 606374500
- E: pr@betacom.com.pl
See also
