Wykorzystanie AI w automatyzacji procesów finansowych.

20 października 2020
Wykorzystanie sztucznej inteligencji w procesach gdzie komputer ma szanse nauczyć się wykonywania zadań naturalnych dla ludzkiego mózgu wkracza w wiele obszarów. Szczególnie te, które z pozoru wydają się proste, ale ich automatyzacja zdecydowanie ułatwia pracę.
Takim też jest projekt, który obecnie realizujemy z wykorzystaniem machine learningu. Jego celem jest automatyzacja procesów finansowych i obiegu dokumentów w organizacji.
Klient zwrócił się do nas z prośbą automatyzacji procesu, gdzie wyzwaniem okazała się ponad setka faktur otrzymywanych dziennie, a obieg dokumentów zakupu oraz ich weryfikacja wymagała czasu.
Standardowo każdy z dokumentów należy w pierwszej kolejności skatalogować według: numeru faktury, daty wystawienia, terminu płatności oraz wartości brutto.
Głównym celem projektu i wykorzystania w tym zakresie sztucznej inteligencji było jednak zidentyfikowanie kontrahenta na podstawie informacji zawartych w postaci elektronicznej dokumentu. W tym przypadku mówimy tu o bardzo zróżnicowanych fakturach, bo zarówno kontrahentów polskich, jak i zagranicznych.
Analiza problemu pozwoliła nam zdefiniować 4 główne elementy procesu.
1. Pierwszym elementem była identyfikacja dokumentów od polskich kontrahentów.
W prawie wszystkich podzagadnieniach należało uzyskać postać tekstową z dokumentów zapisanych w formie plików formatu pdf. Użyliśmy do tego celu mechanizmy rozpoznawania tekstu (ang. OCR), wykorzystujące sztuczną inteligencję, a w szczególności ulepszoną wersję rekurencyjnych sieci neuronowych (LSTM ang. Long Short-Term Memory).
W ten sposób otrzymaliśmy reprezentację tekstową faktury i w prosty sposób zidentyfikowaliśmy kontrahentów wykorzystując NIP jako główny atrybut.
2. Drugim elementem procesu była identyfikacja dokumentów od kontrahentów zagranicznych.
Istotną częścią projektu było rozpoznanie kontrahenta na podstawie faktury zagranicznej. W tym przypadku wykorzystaliśmy modele sztucznej inteligencji (ang. AI) bazujące na uczeniu maszynowym. Algorytmy te nie operują się jednak na danych tekstowych. Potrzebny więc był model przekształcający nasze dokumenty na postać liczbową. W pierwszym etapie przygotowaliśmy nasze próbki (ang. preprocessing). Następnie przekształciliśmy tekstową postać zbioru wejściowego dokumentów (ang. corpora) na jego reprezentację wektorową.
Pomocną do uzyskania jak najlepszego modelu była macierz podobieństwa (ang. similarity matrix), obrazująca za pomocą heatmap-y stopień podobieństwa między fakturami wykorzystanymi do utworzenia modelu a przykładowymi, nowymi dokumentami.
Dla pierwotnej wersji modelu otrzymaliśmy heatmap-ę gdzie każda z kolumn przedstawia wzorcową grupę faktur danego kontrahenta. Każdy z wierszy pokazuje więc stopień podobieństwa nowej faktury do każdej z wzorcowych grup (czym kolor ciemniejszy kolor tym podobieństwo jest większe).
Poniższy rysunek przedstawia 16 kontrahentów (klastry faktur zagranicznych) oraz 16 nowych faktur.
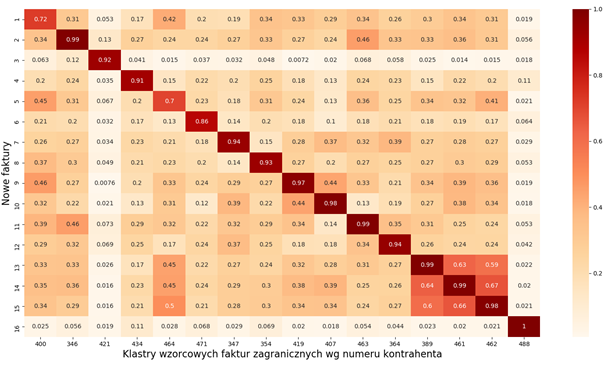
Po modyfikacjach modelu otrzymaliśmy postać wektorową dokumentów, która jest wystarczająca do jednoznacznego przypisania nowych faktur do grupy wzorcowej:
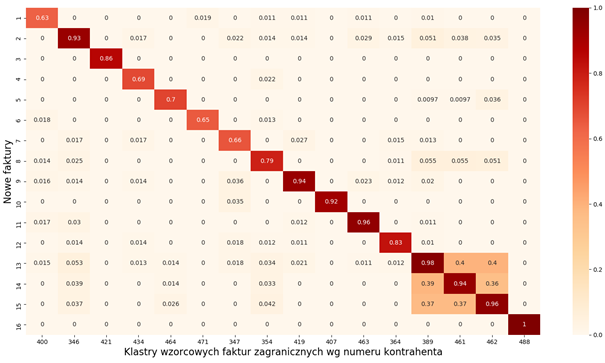
Otrzymany model został wykorzystany do wyliczenia postaci wektorowej nowo otrzymanych dokumentów. Dla tak otrzymanej reprezentacji dokumentu użyliśmy metody znajdującej najbardziej podobny wektor z naszego zbioru wejściowego – otrzymując w ten sposób szukanego kontrahenta zagranicznego.
3. Trzecim zidentyfikowanym elementem procesu było pobranie informacji typu: numer faktury, data wystawienia itp.
Wykorzystaliśmy w projekcie modele uczenia maszynowego (ang. Machine Learning), w tym techniki przetwarzania języka naturalnego (ang. NLP) do pozyskania informacji podstawowych takich, jak numer faktury, data wystawienia i otrzymania. Oparte o sieci neuronowe modele word2vec, pomogły nam odnajdywać w dokumencie słowa najbardziej zbliżone do ich wzorcowej postaci.
Podobnie jak na poniższym schemacie (źródło: https://nlp.town/blog/sentence-similarity/)
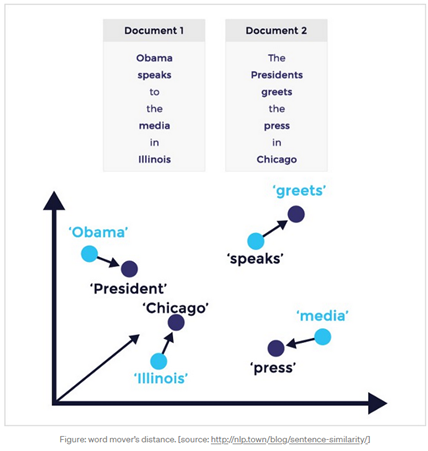
Konsekwencją tego działania było zidentyfikowanie obszarów w tekście, które zawierały poszukiwane dane. Aby uniknąć błędnej identyfikacji obszarów, nasz algorytm doucza się z każdą nową fakturą, porównując swoją propozycję z danymi zaakceptowanymi przez użytkownika systemu.
4. Czwartym elementem procesu jest opisanie faktury z powiązaniem do artefaktów biznesowych.
Odmiennych metod użyliśmy do automatycznego opisywania dokumentów. W tym przypadku potrzebowaliśmy skutecznego algorytmu, rozpoznającego pozycje zapisane na fakturze. Wykorzystaliśmy techniki przetwarzania obrazów (ang. image processing). Pozwoliło nam to znaleźć, dzięki porównaniu z obrazem wzorcowym, współrzędne geometryczne wszystkich pozycji nowo otrzymanej faktury.
Poniżej przykład użycia tej metody do znajdowania monet:

Dla tak otrzymanych obszarów, użyliśmy metod grupujących znaki dokumentu, otrzymując w ten sposób pozycję faktury podzieloną na kolumny. Następnie, zaprojektowaliśmy interfejs konfigurowalny przez użytkownika, umożliwiający mapowanie otrzymanej tablicy na artefakty biznesowe.
Opisane metody zaimplementowaliśmy w języku Python. Do integracji wybraliśmy architekturę opartą na komunikujących się ze sobą serwisach. Serwisy napisane w języku Python komunikują się z pozostałymi modułami aplikacji zapisanymi w technologii Microsoft.Net.
Nasi specjaliści tworzą takie rozwiązania, które są w stanie uczyć się samodzielnie by szybko i jak najlepiej rozwiązać konkretne zadania.
Jak wykorzystać możliwości AI w Twojej organizacji ?
Więcej informacji – zapraszamy do kontaktu betacom@betacom.com.pl
Udostępnij
Kontakt
- Dariusz Styka
- T: +48 606374500
- E: pr@betacom.com.pl
Zobacz także
